ِBig Dataتطور ال : Apache Spark من مكتبة الإسكندرية إلى ال


البداية
بدأ تاريخ الBig Data من وجهة نظري وقت مكتبة الإسكندرية القديمة لما دعى (بلطيموس الأول) كتّاب و مؤرخين العالم يجوا يعيشوا ف إسكندرية على حسابه و بعدها فرض (بطليموس الثالث) سياسة ان أي سفينة تيجي عند ميناء إسكندرية يسلموا كل المخطوطات و الكتب للمكتبة ينسخوها و المكتبة تحتفظ بالأصل.

الموضوع وصل ان عين ناس تلف دول البحر الأبيض المتوسط تشوف مخطوطات و كتب و أي عمل أدبي و ينسخوه للمكتبة و منع تصدير ورق البردي لبرة عشان الناس تضطر تيجي مصر و تكتب. لأول مرة في التاريخ كان فيه indexation او فهرسة للكم ده من المعلومات في مكان واحد.

و دي المشكلة اللي لقت جوجل نفسها في مطلع القرن الجديد انهم عايزين يفهرسوا كل المقالات و المدونات عالنت .. ف إخترعوا كذا حاجة زي
Indexation of WWW
Google File System (GFS): و ده distributed system شغال على كذا cluster
Bigtable: و ده scalable store بيستعمل الGFS
MapReduce
- MapReduce: و دهparallel data processing technique لو عندك طبق كشري .. عايز تعد فيه كام حباية رز و عدس و حمص بدل ما تعد البقوليات دي serially .. حتدي كذا معلقة كشري لكل شخص من صحابك .. كل واحد فيهم حيcalculate الرز و بعدين ي report ليك.
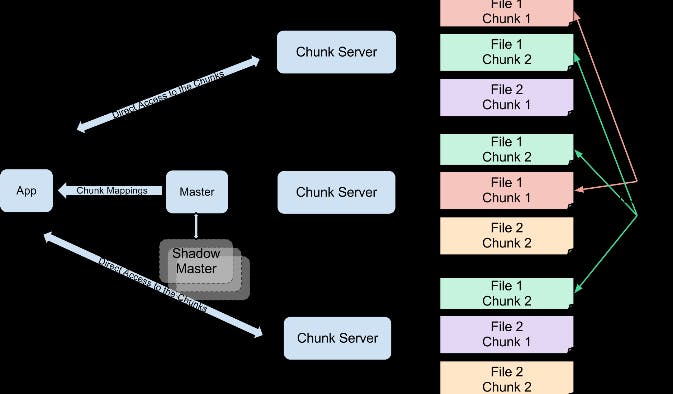
حتقوم واخد كل واحد فيهم عد كام حباية رز و كام عدس و إلخ .. و بعدين تقوم مقسم كل واحد فيهم per بقولية .. صاحب حيبقى مسئول عن تجميع عدد الرز .. صاحب حيبقى مسئول عن تجميع عدد الحمص .. و هكذا صحابك لما عدوا الكشري و هو متلخبط كانوا Mappers معلقة الرز هي fraction of data.
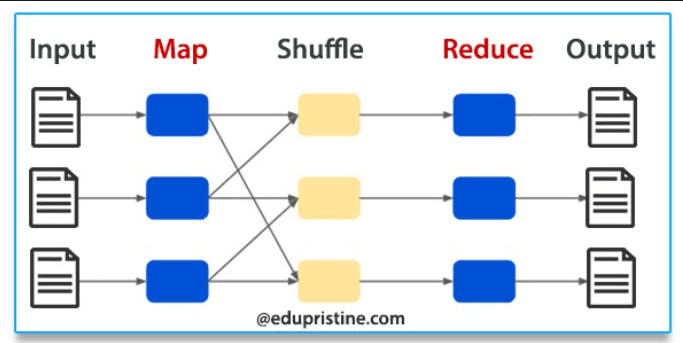
و هما بيعدوا البقوليات ده الMapper job لما قسمتهم per بقولية دي اسمها shuffling لما كل واحد جمع total number of رز و عدس و حمص ده reduce. الMapeReduce أول ما إخترع كان شغال بengine اسمه Apache Hadoop و جوجل برضه هي اللي كانت مخترعاه بس مكنتش عاملاه open source

لكنها نشرت الأبحاث اللي اتكتبت و اللي أدت للMapeReduce و الHDFS او Hadoop Distributed File System .. بعدها المهندسين ف Yahoo كتبوا كود بناءًا على الأوراق البحثية دي و حطوه كopen source بالApache License. المشكلة بتاعة MapReduce انه بطيء عشان كل stage بيread و يwrite للdisk
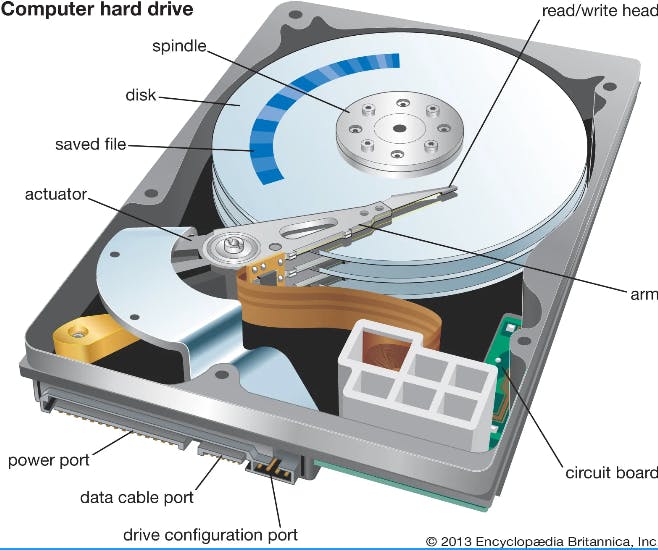
Disk Vs RAM
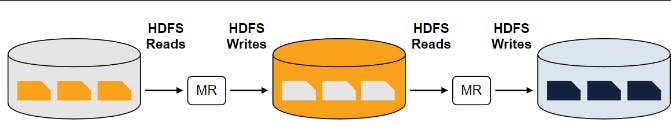
الHard disk أبطىء من الRAM عشان هو معمول من magentic material و الarm بياخد وقت عقبال ما يلاقي الdata اللي عالdisk فيما حين ان الRAM معمول من transistors و semi conductors ف الsignlas بتاخد وقت أسرع

موضوع بطىء الMapReduce ده واحد اسمه Matei Zaharia في جامعة UC Berkeley لاحظه و كتب بحث عن enginer جديد اسمه Spark بيستعمل الMemory بدلاً من الhard disk و إتكلم ان فيه 3 حاجات MapReduce paradigm مش بيدعمها كويس و Spark أحسن منه فيها:
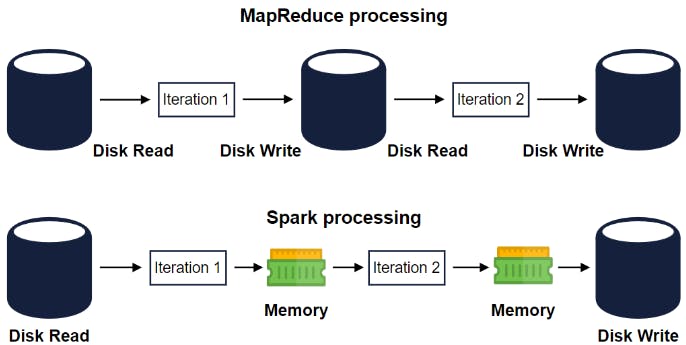
محدوديات MapReduce
Iterative Jobs: في حالة الMachine learning ف الalgorithms بتعدي كذا مرة على الداتا و بتضطر تread من الhard disk كل مرة و ده مكلف في الوقت.
Interactive Analysis: لو بتعمل كذا SQL queries على dataset حجمها كبير عشان تعمل analysis ليها ف الlatency حتبقى عالية.
Rich APIs: في الMapReduce بتضطر تكتب boilerplate code كبير عشان تبتدي تستعمله فيما حين ان الSpark بيقدم APIs حتinvoke it و خلاص
بيحلها Spark ال Use Cases كمان طرح
Parallel processing of large data sets across clusters.
Analyzing large data sets: و ده بيبقى مطلوب من اول الe-commerce لحد الsocial network products
Building, training, and evaluating machine learning models.
Creating data pipelines بغض النظر عن ايه الdata source
الdata structure اللي من خلالها اي data بيتم تمثيلها في Spark اسمها RDD او Resilient Distributed Datasets بتبقى immutable و ممكن تتقسم على كذا cluster و تشتغل in paraller و لو cluster وقع ف ممكن يتعملها re-construction.
Architecture of Spark
Spark عنده نفس نظامmaster-slave architecture زي MapReduce بحيث ان الmaster هو اللي بينظم الdistributed work و الslave هو اللي بيprocess
اسم الmaster هو Driver مهمته يقرا الcode من الuser بعدين يحوله ل Directed Acyclic Graph او DAG عشان ي optimize و يعرف انهي step تبقى قبل نهون
بعد كده بيدي الorders للslaves و اسم الslave ف Spark هو Executor الExecutor بياخد الcode من الDriver و بيreport الstate بتاعة الcomputation بتاعتها و مهمة الDriver انه يkeep track من شغل كل Executor
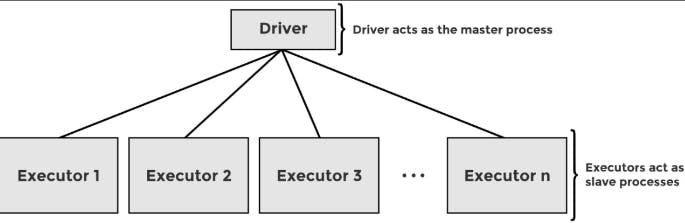
آخر component ف Spark هو Cluster manager .. سواء شغال MapReduce او Spark ف الjobs بتبقى شغالm على cluster of machines .. الDriver بتاع Spark ميقدرش يallocate resources من الcluster ف بيبقى فيه Cluster manager لده الDriver بعد كده بيتفاوض مع الCluster manager و يوفرهم للExecutors
من أمثلة الCluster Managers
Local mode: ده لو عايزة تجربي على الكومبيوتر حجك
Built-in standalone cluster manager: لو شركتك بانية Cluster Manager بنفسها او شغالة on premise
Hadoop YARN
Kubernetes
Apache Mesos
لو حنراجع على ال الApplication Lifecycle بتاعة الSpark job فهي كالتالي: ك user بتsubmit ال spark job لل cluster manager و بيقول للDriver اصحى عندك طلعة. في الوقت ده الCluster Manager بيspawn كذا Executor nodes و بيرجع الlocations بتوعهم للDriver عشان يعرف يكلمهم.
بعدها الDriver بيحول الcode لDAG و يقول لكل Executor Node ت execute ايه و يعرف الstatus أخيرًا لما كل Spark Job بتخلص الCluster manager بيshutdown كل Executor node بالنيابة عن الdriver
و بس كده يا قمامير أتمنى تكونوا إستفدتم و لو قلت معلومة خاطئة حبقى مبسوط لو حد صصحهالي
Hope you found this useful 😊
المصادر:
https://www.youtube.com/watch?v=jvWncVbXfJ0&ab_channel=TED-Ed
https://www.educative.io/courses/introduction-to-spark
https://www.edupristine.com/blog/hadoop-mapreduce-framework
https://en.wikipedia.org/wiki/Matei_Zaharia
https://www.britannica.com/technology/hard-disk