Distributed Key-Value Storeل system design إزاي نعمل


Table of contents
لو حنيجي نعمل system design ل key-value store زي DynamoDB او redis او memcache ف الأول نعرف ايه مميزاتها و اللي بيفرقها عن الRelational Database العادية
لو داخل على تويتر و عامل الdisplay يبقى dark mode ف بيبقى فيه entry ف ال key-value store بتاعة تويتر بيدور على الsession الخاصة بيك و بيشوف من الcookie ايه تفضيلاتك.
استعمال تاني ليه في الe-commerce websites لو انت حاطط حاجات ف الcart بتاعتك ف بيخزن الitems دي ك value ف الkey-value store بحيث لو قفلت الtab و فتحت الويبسايت تاني حتلاقي حاجتك موجودة
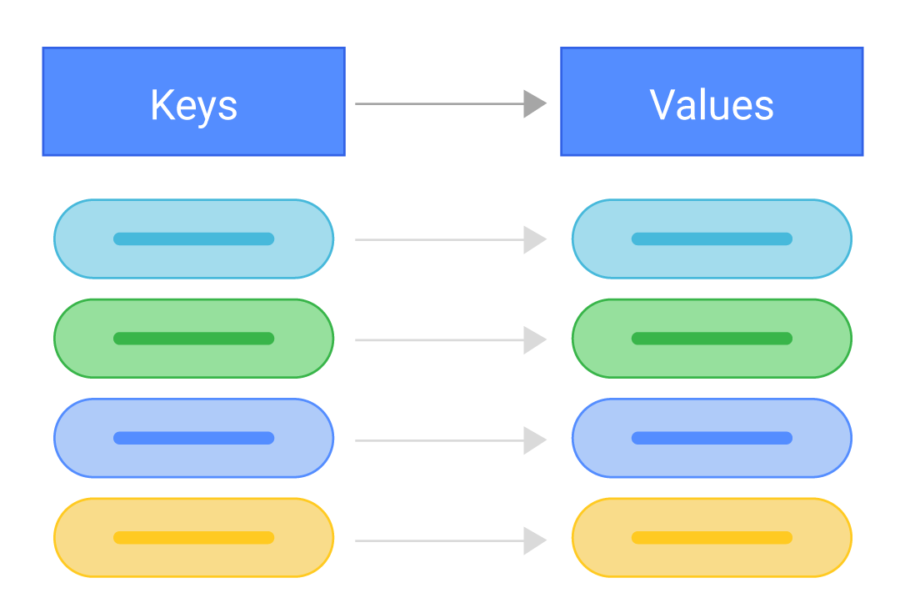
المتطلبات
1- حجم الrecord الي هو عبارة عن key-value pair يبقى ثغنن ميعديش
10kb 2- الstore يقدر يخزن big data و ده حيتحقق لو الrecords حجمها صغير
3- High availability بحيث اننا نقدر نinsert و نget الداتا ف أي وقت
4- Automatic Scaling لو حنشيل أو نحط سيرفارات بتاعة الdata store ف الموضوع يبقى أوتوماتيكي و منعملش migration بإيدينا
5- Tunable Consistency
الconsistency بتاعة الداتا يا بتبقى strong يا بتبقى eventual .. حنشوف ايه الفرق بين الاتنين و ازاي نتحكم ف الconsistency بتاعتنا
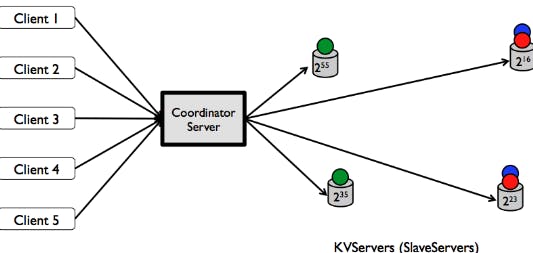
لو حنستعمل سيرفر واحد يبقى عليه الdatabase (اللي هي في حالتنا دي الkey-value data store) ف مش حيقدر يوفي الrequirements عشان حيوصل لstorage limit بتاعه ف لازم نستعمل كذا سيرفر و حنعمل Distributed Key Value Data Store🤷♂️
المكونات الأساسية للdistributed system ده هما
1. Data Partition
2. Data Replication
3. Consistency
4. Handling Failures
1- Data Parition
حنوزع الdata بتاعتنا على كذا سيرفر و لازم نعمل حسابنا اننا لو أضافنا أو شيلنا سيرفر منعملش data migration كتير .. لأن دي عملية مكلفة و ممكن حاجات كتير غلط تحصل و الداتا بتاعة الusers تضيع للأبد + بتأثر عالavailability. عشان نحقق ده محتاجين Consistent Hashing
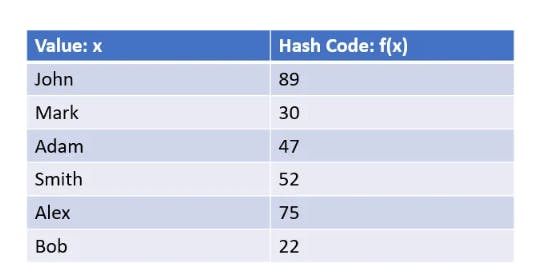
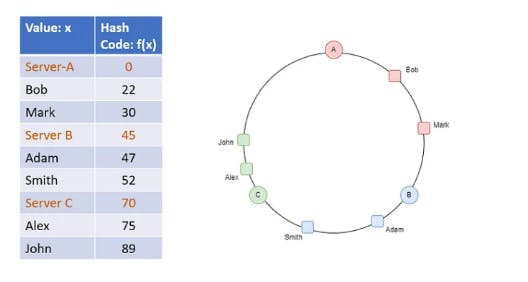
الhashing ف الMap في الjava او الDictionary في الC# هو زي تشفير للداتا بحيث لو الداتا بsize مختلف عن بعضه (يعني الlength بتاع اسمي مصطفى بيتخلف عن length اسم أحمد) ف الhashing بيوحد الlength بتاعنا و بيبقى اسمع hashcode
الhashing ف الDistributed system بيختلف سيكا عشان هو بيقول الداتا دي متخزنة على أنهي سيرفر.
ممكن مثلا تفكري اننا نخزن الناس اللي اسمهم بيبدأ من حرف A-H عند اول سيرفر بعدين الناس اللي من I-P عند تاني سيرفر و هكذا.
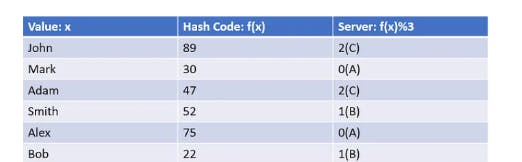
مشكلة الطريقة دي انها بتخلق hot spots عشان لو معظم الusers عندنا اسمهم محمد ف كده حيبقى فيه ضغط كبير على السيرفر التاني عشان هو ضامم الحروف من I-P ف محتاجين نrandomize الحوار ده .. عشان كده بنخزن على حسب الrange بتاع الhashing
يعني سيرفر 1 بيخزن اسامي الناس اللي الhash code بتاعها من 10-20 و سيرفر 2 بيخزن من 21-31 و هكذا .. ف السيرفر مبيهمهوش الvalue بتاعة الداتا لكن بيهمه الhashcode بتاعتها و دي حاجة كويسة عشان المفروض السيرفر يبقى agnostic للداتا عشان الprivacy و كدزه
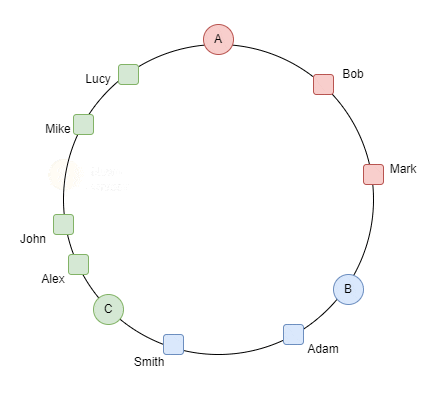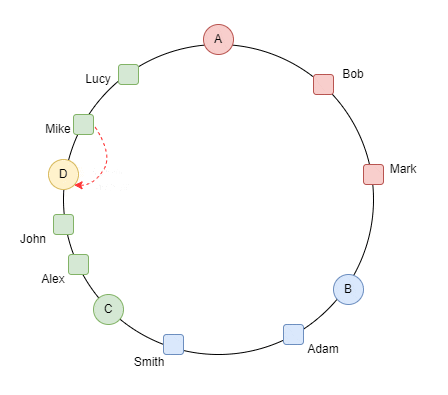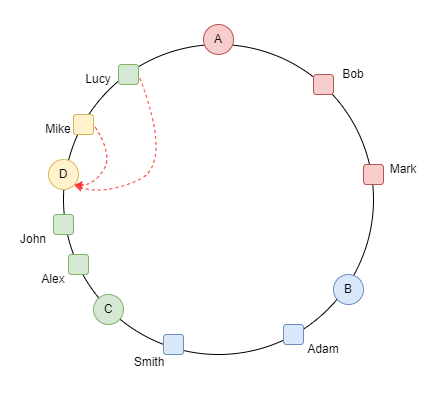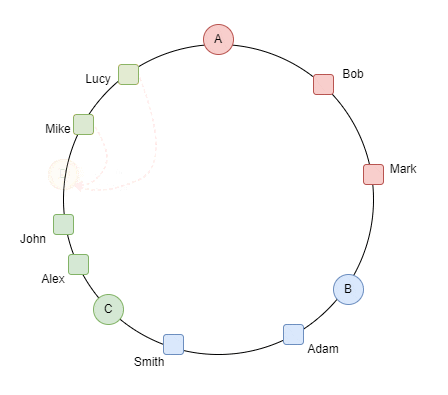
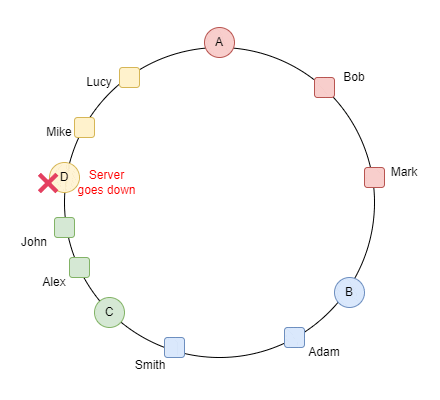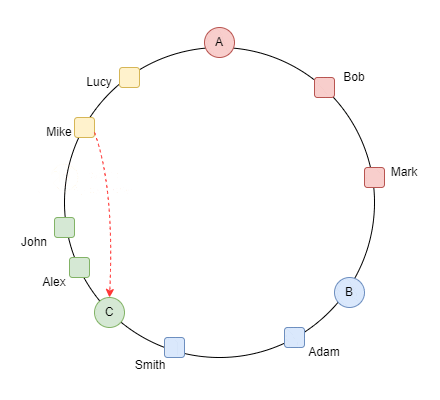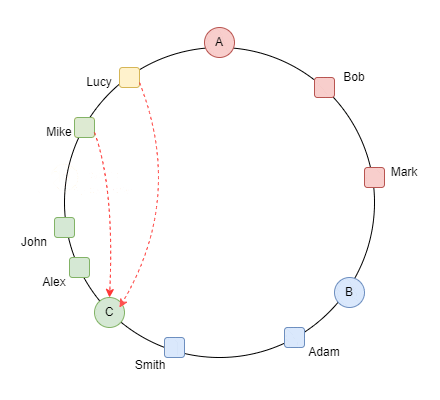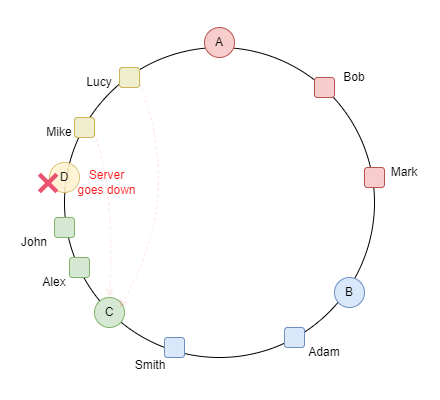
لو بصينا للgif ده بنتخيل ان السيرفرات على شكل ring بدل table و لو حطينا سيرفر رابع .. ف كل الداتا اللي قدام الserver clockwise بتروحلها و بننقلها من السيرفر القديم اللي هو C و نcalculate الhashcode الجديد بتاعهم بعدين ننقلهم للسيرفر الجديد D
الproperty دي اسمها monotonicity
دي حاجة جميلة جدًا عشان متضرناش اننا نcalculate الhasing بتاع كل الداتا و الdata migration كان قليل لو حصل و سيرفر وقع ف الداتا اللي كانت عليه بتروح للسيرفر القريب منها anti clockwise كده احنا حققنا requirement ان الdatabase تبقى auto scalable
2- Data replication
عشان نبقى realible و available و سخنين و بسمسم ف الdata محتاجة يتعملها backup (اللي هو replication) في سيرفرات تانية .. بنحقق ده ان لما data يتعملها update او insert ف بنعمل replication في او سيرفرين(ممكن أكتر) ف اتجاه عقارب الساعة clockwise في الring
و يستحسن في الinfrastructure يبقى فيه سيرفرات من data centers مختلفة عشان لو مثلا السيرفرات كلها في ولاية فيرجينا في أمريكا و الولاية دي حصل فيها إعصار أثر عالdata center ف كده السيرفرات الأساسية و الreplicas راحوا 😃
3- Consistency
معنى الConsistency يعني لما أكتب حاجة في الداتابيز .. و بعدين أقراها .. حلاقي الvalue اللي أنا لسه كاتبها
Consistency is reading the most up to date data. و دي بتبقى مطلوبة لو مثلا بتعمل payment application
ال3 انواع لل consistency models هما
Strong concistency:
اي read operation لازم ترجعلي most updated write data item
Weak consistency: مش لازم الread operation تشوف الmost updated value
Eventual consistency: بعد شوية وقت الread operation حتشوف الmost updated value

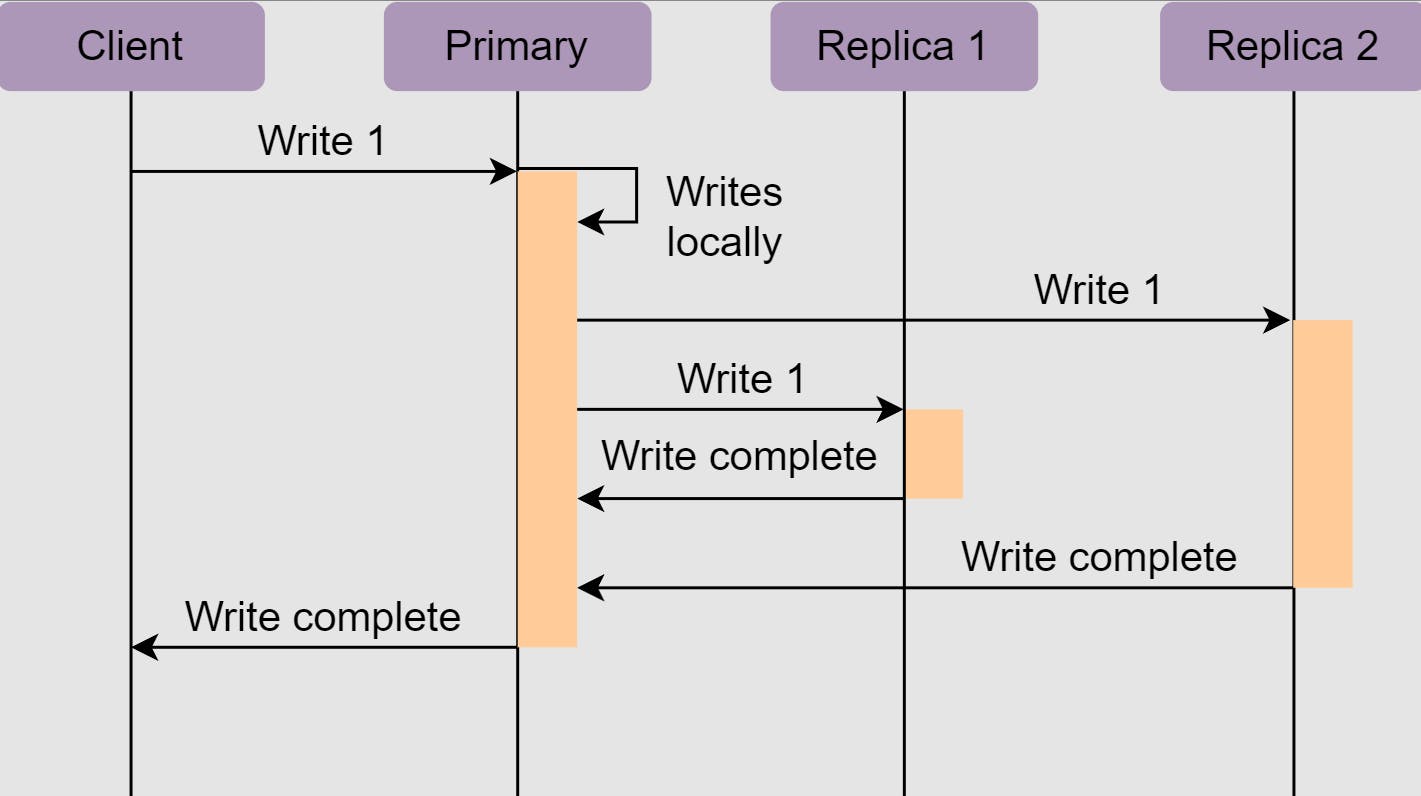
عشان نحقق الconsistency ف لازم الداتا اللي في الreplicas تبقى updated .. ممكن تعمل ده ب synchronus replication يعني الwrite operation حتستنى لحد ما تwrite ف كل الreplicas بعدين تقولك تمام
المشكلة ان لو replica واحدة فشلت تwrite ف كده كل الoperation فشلت و حيأثر عالavailability
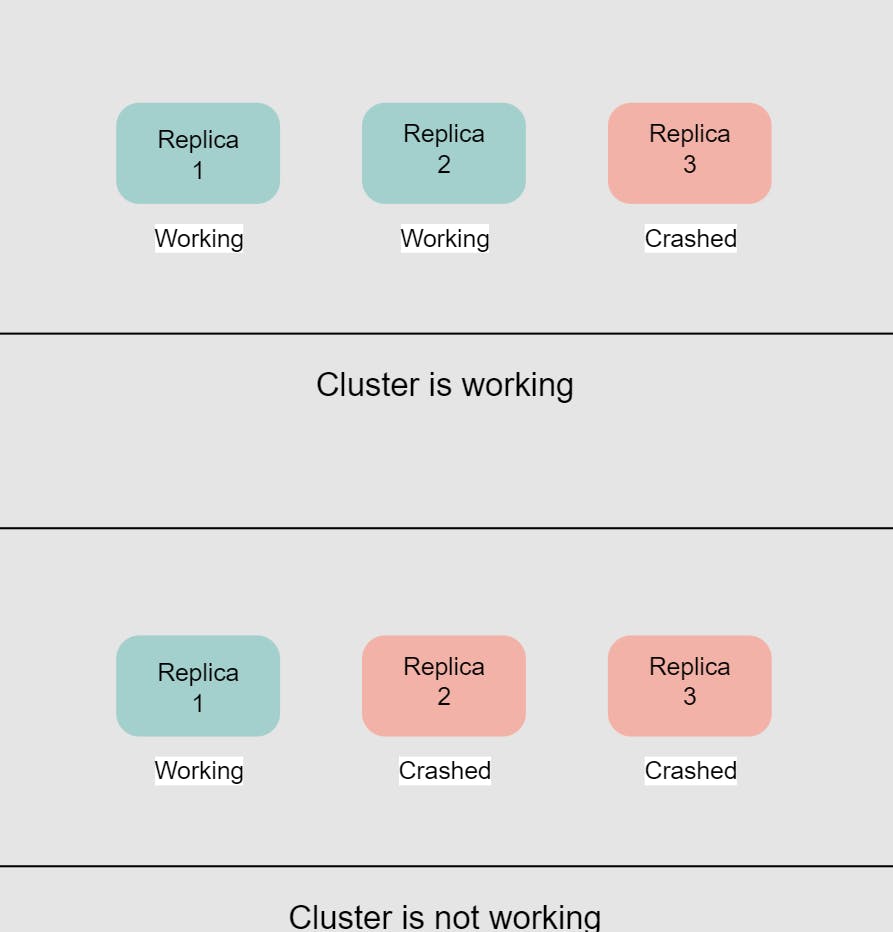
حل الموضوع ده حاجة اسمها Quorum .. الإسم يخض 😃 معناه أقل عدد من الreplicas عشان على أساسها نحدد الRead/Write Transaction نجح ولا لأ لو انت في خروجة مع صحابك و انتوا تلاتة عايزين تخشوا فيلم .. ف لازم عالأقل 2 منكوا يبقوا عايزين يخشوا نفس الفيلم و تبقى أغلبية .. التالت مش مهم
ف الQuorum هو العدد المطلوب من الreplicas تAck operation معينة عشان الoperation تنجح ف لو عندك 3 replicas الأحسن تخلي الQuorum ب 2 لو عندك 5 replicas ف خليهم 3
آخر Requirement نحققه هو الTunable Consistency و اللي حيساعدنا في ده هو الQuorum consensus
N: عدد الreplicas
W: حجم الQuorum للwrite operations (يعني العدد المطلوب من الreplicas اللي تAck الwrite operation عشان نقول ان الoperation نجحت)
R: حجم الQuorum لل read operations
الconfiugration بتاع ال W و الR بيحددوا الconsistency level و الlatency ف مثلا لو
W+R > N معنى كده ان فيه strong consistency عشان معنى كده ان فيه عالأقل replica واحدة بت overlap بين الW و الR replicas و حيبقى عندهم الmost updated data
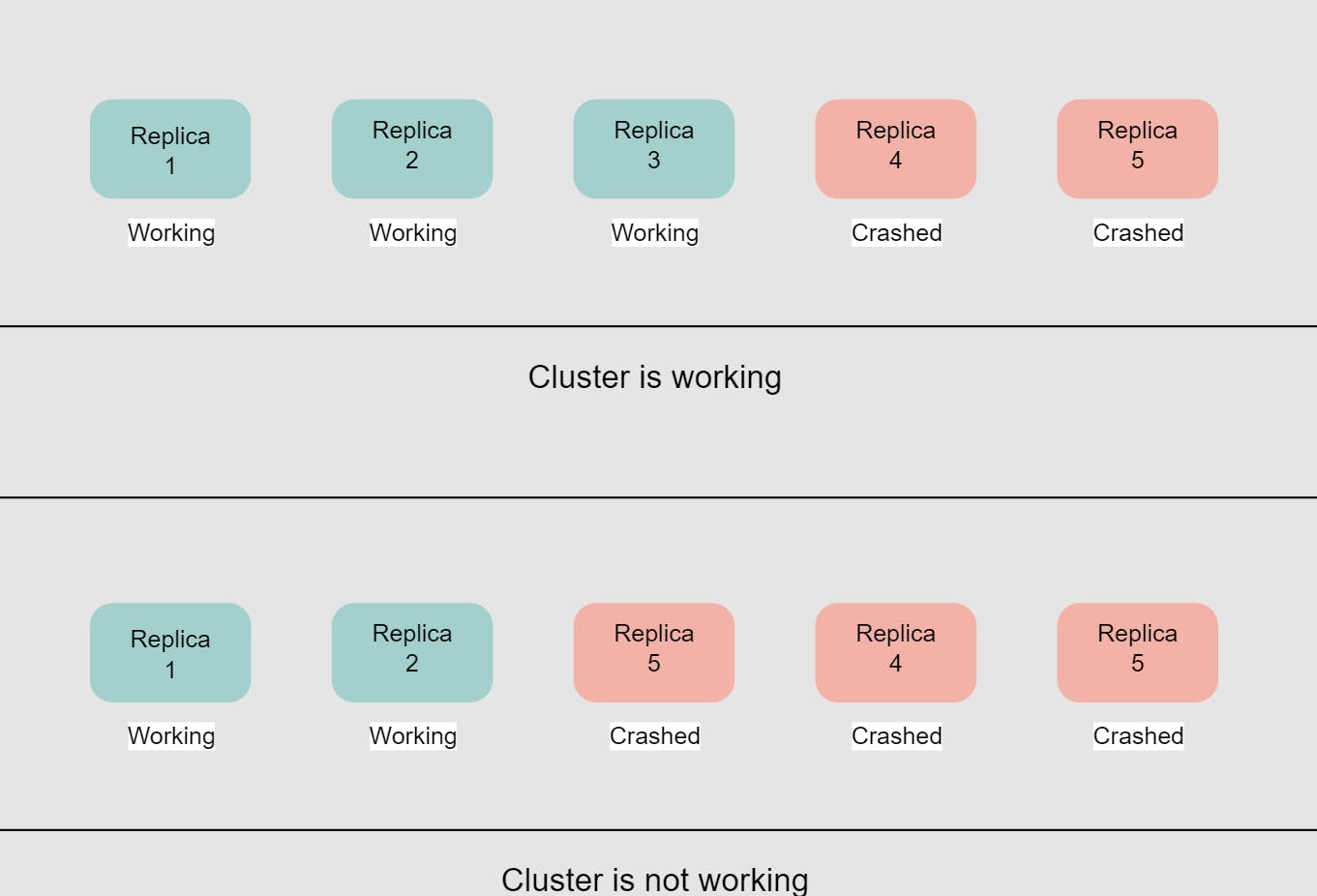
لو عندنا مثلا عدد الreplicas N = 5 W = 3 R = 3
ف W+R > N عشان لازم عالأقل 3 nodes يتفقوا عالread operation و 3 nodes يتفقوا عالwrite operation ف فيه node بتoverlap بينهم و ده اللي عندها strong consistency
R = 1 و W = N ف السيستم معمول لل fast read احنا لسه حن replicate xD
R = N و W = 1 ف السيستم معمول لل fast write
W + R <= N eventual consistency
و بكده نكون خلصنا الrequirments بتاعة الsystem design ل distributed key-value store أتمنى تكونوا استمتعوا :D
المصادر
System Design Interview – An insider's guide by Alex Xu
https://www.educative.io/answers/what-is-quorum-in-distributed-systems
https://www.scylladb.com/glossary/key-value-store/
https://levelup.gitconnected.com/consistent-hashing-in-action-e9637114f0d1
https://inst.eecs.berkeley.edu/~cs162/fa13/phase4.html
https://www.techtarget.com/searchdatamanagement/tip/NoSQL-database-types-explained-Key-value-store
https://www.influxdata.com/key-value-database/